close
話不多說,今天要到SPACE WEATHER PREDICTION CENTER爬蟲x-ray flux,至於這件事有甚麼意義,可以隨便請教你認識有在教微氣候學的老師,他們都可以回答你的問題。
(連結:https://www.swpc.noaa.gov/products/goes-x-ray-flux?fbclid=IwAR0fhIxZFgOXFfTvuC3jLn9WspYURfTDuFiIizJukKbceNia9d94NGA9uJE)
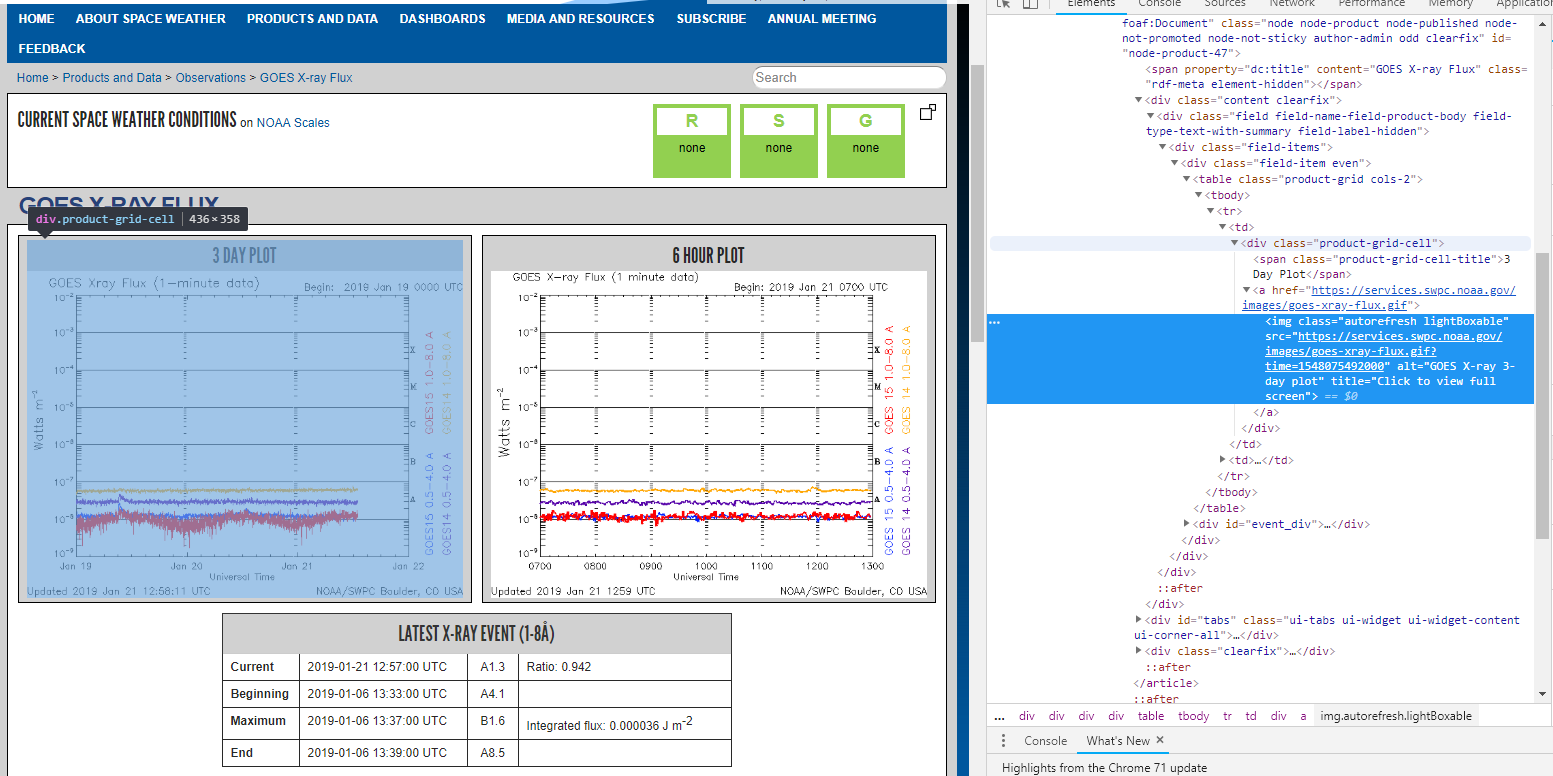
一樣,先檢查原始碼,發現gif的圖檔位在一個<div class="product-grid-cell">下面的<img>標籤,該圖的連結在標籤內的src屬性裡面,圖檔的名稱則是alt屬性。
所以我們一樣利用selenium開啟模擬瀏覽器,用BeautifulSoup解析原始碼,進入到目標的div標籤之後,使用urllib.request.urlretrieve把圖檔給載下來。
在來就是就是圖的下方有一個測量flux的表格,我們希望把表格的內容寫進csv檔裡面。檢查原始碼發現,表格被放在<table id = 'event_table'>裡面,一樣進入到該標籤後,把每一個欄位的內容取出做成一個list之後,用writerow寫入csv檔之中。
執行完之後的結果:
下載下來的圖片會跟.py檔在同一個資料夾裡面。
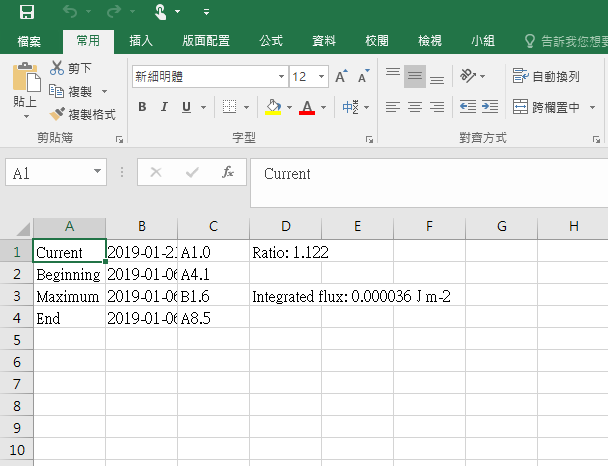
csv檔裡面的內容就會像這樣。
程式碼:
# coding: utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
import datetime
import urllib.request
import urllib
import csv
#x-ray flux
url = 'https://www.swpc.noaa.gov/products/goes-x-ray-flux?fbclid=IwAR0fhIxZFgOXFfTvuC3jLn9WspYURfTDuFiIizJukKbceNia9d94NGA9uJE'
#開啟模擬瀏覽器
driver = webdriver.Chrome()
driver.get(url)
#用lxml解析原始碼
soup = BeautifulSoup(driver.page_source, features='lxml')
driver.quit()
#進到<div>,因為圖有兩張,所以是find_all
divs = soup.find_all('div',{'class':"product-grid-cell"})
for div in divs:
#取得圖檔連結
href = div.a['href']
#圖檔名稱
pic_name = div.img['alt']+'.gif'
#下載圖片
data = urllib.request.urlretrieve(href,pic_name)
table = soup.find('table',{'id':'event_table'})
trs = table.tbody.find_all('tr')
#'data.csv'是要寫入的檔名,'a'代表append,用'r'會寫掉之前的內容
with open('data.csv', 'a',newline='') as f:
writer = csv.writer(f)
for tr in trs:
divs = tr.find_all('div')
a = []
for div in divs:
#把資料彙集成一個list
a.append(div.text)
#寫入資料
writer.writerow(a)
#關閉文件
f.close()
全站熱搜

 留言列表
留言列表
